Data Integrity Standards For Production-Ready Apps
Data integrity is critical for production apps. It ensures your data stays accurate, consistent, and reliable, which is essential for user trust, compliance, and preventing costly errors. Here's what you need to know:
- Key Risks: Human errors, system failures, and security breaches can compromise data integrity.
- Framework: The ALCOA+ principles - Attributable, Legible, Contemporaneous, Original, Accurate, Complete, Consistent, Enduring, and Available - are essential for reliable data management.
- Best Practices:
- Use input validation and automated checks to catch errors early.
- Implement role-based access controls and maintain detailed audit trails.
- Back up data with point-in-time recovery options and test restoration processes regularly.
- Encrypt data at rest, in transit, and in use for added security.
- Tools: Platforms like AWS Glue and Snowflake offer features like checksum validation and automated monitoring to help maintain data quality.
Data Integrity Tests in CI/CD Pipelines Christopher Crow, Portworx & Stephen Atwell, Armory.io
Automating these tests is essential when you build revenue-generating apps that require high data reliability.
sbb-itb-c336128
The ALCOA+ Framework for Data Integrity
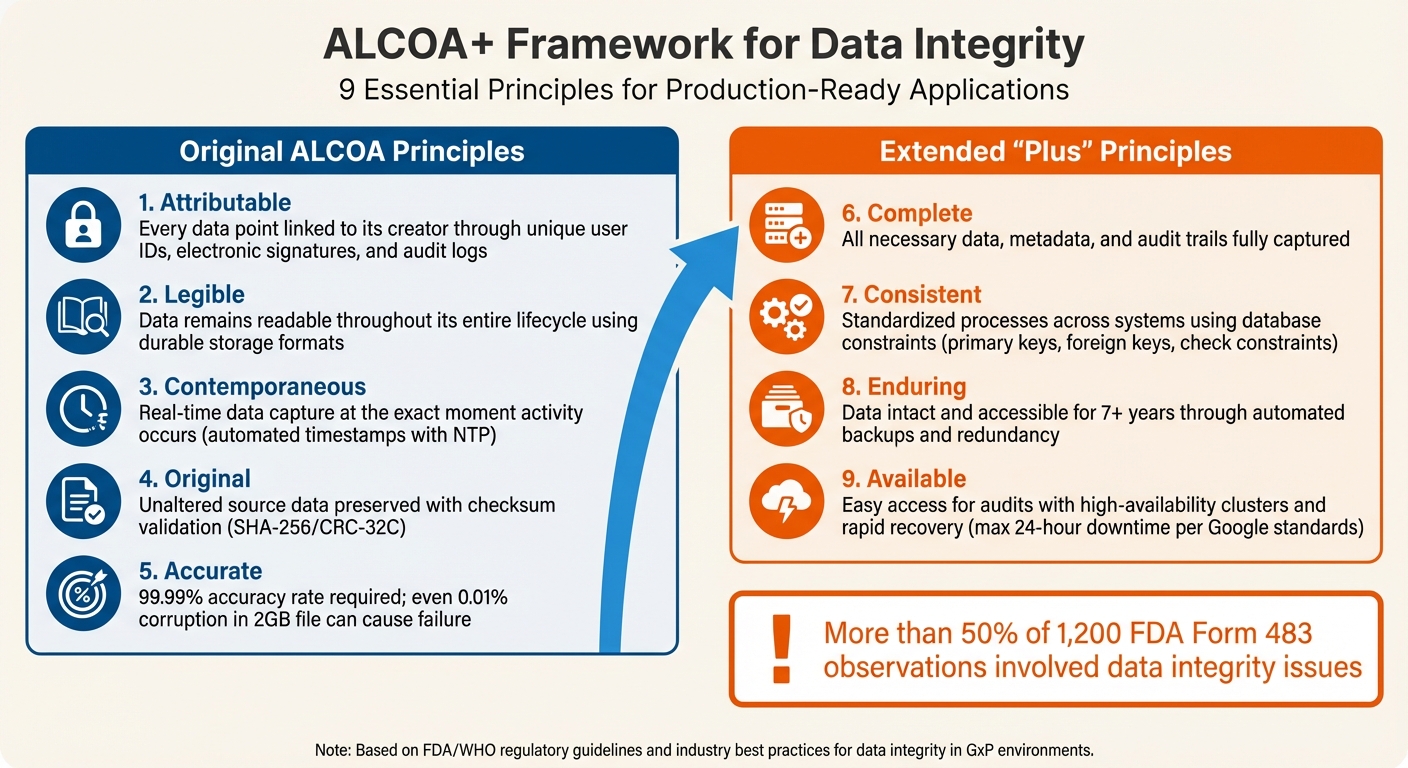
ALCOA+ Framework: 9 Principles for Data Integrity in Production Apps
The ALCOA+ framework is a standard for ensuring the integrity of production data. While it was initially created for pharmaceutical manufacturing, it has since become the baseline used by the FDA (under 21 CFR 211.68 and 211.100) and WHO to assess whether records can be trusted [6]. The acronym ALCOA stands for Attributable, Legible, Contemporaneous, Original, Accurate, with the "+" adding Complete, Consistent, Enduring, and Available.
A review of 1,200 FDA Form 483 observations revealed that more than half involved data integrity issues, particularly around original data, attribution, and accuracy [6]. For production applications handling financial transactions, patient records, or user data, following these principles can help avoid critical failures.
"ALCOA attributes provide the framework FDA uses to judge whether records are reliable and trustworthy." - Redica Systems [6]
This framework not only outlines what data should be recorded but also focuses on its protection. While the original ALCOA principles emphasize accuracy and proper data creation, the "+" elements address modern challenges like distributed systems, long-term storage, and ensuring continuous availability. Together, they form a solid foundation for managing data in production environments.
Attributable and Traceable Data
Every piece of data should have a clear connection to its creator. Attributable means it must be possible to identify who created or modified the data at any point. This is typically achieved through unique user IDs, electronic signatures, and detailed audit logs. Databases should automatically record user IDs and timestamps for all actions, such as inserts, updates, or deletions. Role-based access control (RBAC) further ensures that only authorized individuals can modify specific data.
Traceable takes this a step further by maintaining a complete history of changes. If a record undergoes multiple modifications, it should be possible to reconstruct each version and understand the sequence of changes. This historical tracking is key to preventing both accidental errors and intentional tampering, ensuring data integrity in high-throughput systems.
Legibility, Permanence, and Real-Time Capture
Legibility ensures that data remains readable for its entire lifecycle. This often involves using storage formats that are durable and accessible over time.
Contemporaneous recording - capturing data at the exact moment an activity occurs - is vital to avoid backdating or manipulation. Automated timestamps, synchronized with tools like NTP (Network Time Protocol), can help enforce this principle.
Google's standards suggest that 24 hours is the maximum acceptable downtime for cloud applications [4].
Originality, Accuracy, and Completeness
Original data must remain unaltered to preserve its authenticity. Automated data capture helps minimize human error, ensuring the original source data is intact. When duplicates are needed, checksum validation ensures that the copy matches the original.
Accuracy demands precision and error-free data. This is achieved through strict input validation, ensuring data is entered in the correct format, type, and range. In high-reliability systems, a 99.99% accuracy rate is often required, as even tiny errors - like a 0.01% corruption in a 2 GB file - can render a database or executable unusable [4].
Completeness means all necessary data, including metadata and audit trails, is fully captured. Each record should include details like who created it, when, and under what conditions, making it valuable for compliance and troubleshooting.
Consistency, Durability, and Accessibility
Consistency ensures that data follows standardized processes and remains uniform across systems. Database constraints like primary keys, foreign keys, and check constraints help maintain logical relationships and prevent issues like orphaned records.
Enduring data must remain intact and accessible for as long as required - often seven years or more in regulated industries. This is achieved through automated backups, redundancy, and archiving strategies designed to withstand hardware failures, software bugs, and media decay. While replication protects against hardware failures, it can also spread corruption, making diverse, point-in-time snapshots essential for true recoverability [4].
Available data must be easy to access for audits, reviews, and inspections throughout its lifecycle. This requires not just reliable backups but also high-availability clusters and efficient recovery protocols. Google's Site Reliability Engineers emphasize:
"The secret to superior data integrity is proactive detection and rapid repair and recovery." - Raymond Blum and Rhandeev Singh, Google SRE [4]
Ensuring fast data restoration is just as important as maintaining backups, guaranteeing that critical information is always within reach when needed.
Common Threats to Data Integrity
Even the most well-constructed systems are not immune to risks that can undermine data integrity. Understanding these vulnerabilities is crucial for creating systems that can withstand potential disruptions.
Human Errors and Manual Processes
Human mistakes often play a significant role in compromising data integrity. Manual data entry, for instance, can lead to typos, incorrect formatting, missing information, or even duplicate entries. These errors can ripple through systems, causing larger inaccuracies over time. Moreover, operator or developer mistakes - such as accidental deletions, misconfigured settings, or software bugs in data processing frameworks like MapReduce or Hadoop - can result in severe data loss. A Google study examining 19 data recovery scenarios revealed that the most common user-visible data loss involved deletions or referential integrity issues caused by software bugs[4].
Configuration errors are another major concern. For example, applying incorrect or unverified inputs can destabilize systems or even cause outages. Consider this: an SLO (Service Level Objective) of 99.99% "good bytes" in a 2 GB file still permits up to 200 KB of corrupted data - an unacceptable scenario for critical files like executables or databases[4].
Rather than attempting to eliminate human error entirely, the focus should shift to designing systems that minimize its impact. Automated validation processes and implementing soft deletion policies (e.g., retaining data for 30–60 days) can significantly reduce risks[4]. Additionally, enforcing database constraints - such as Primary Keys, Foreign Keys, and Check constraints - alongside validation checks for data type, format, and range at entry points can help prevent invalid data from entering the system.
Unauthorized Access and Security Breaches
Security vulnerabilities represent another major threat to data integrity. Unauthorized access allows bad actors to manipulate, delete, or steal sensitive data, undermining its accuracy and dependability - key pillars of data integrity[8]. Such breaches can distort reports and analyses, leading to flawed business decisions and a weakened competitive edge[8].
The damage extends beyond immediate inaccuracies. Repeated breaches erode trust, disrupt decision-making, and may result in non-compliance with regulatory standards, exposing organizations to hefty fines and legal ramifications[8].
System Failures and Integration Issues
Technical failures also pose a significant risk to data integrity. Hardware issues - like server crashes due to overheating, power outages, or defective components - can disrupt ongoing processes and lead to data corruption or loss[10]. Similarly, software-related problems, such as application crashes or failed updates, can trigger widespread disruptions. Bugs in business logic or mismatched software versions can introduce subtle errors that may go unnoticed for extended periods[4][10].
Integration challenges add another layer of complexity. Transforming data between incompatible formats can result in errors, loss, or corruption during the process[9]. With an estimated 328.77 million terabytes of data generated daily, managing integration at this scale has become a critical task[9]. Legacy systems, often lacking modern security measures or APIs, exacerbate the problem by creating isolated data silos and increasing the likelihood of inconsistencies[8][10].
While replication can improve availability, it doesn’t guarantee recoverability. Automated syncing, for instance, might inadvertently propagate corrupted or deleted data across all replicas in a matter of seconds[4]. As Raymond Blum and Rhandeev Singh aptly put it:
"From the user's point of view, data integrity without expected and regular data availability is effectively the same as having no data at all"[4].
How to Implement Data Integrity Standards
To keep production systems reliable, it’s essential to integrate input validation, enforce strict access controls, and establish strong recovery mechanisms. These measures help identify issues early and ensure data can be restored quickly. Let’s break down the key practices that safeguard data integrity from the moment it enters your system.
Input Validation and Automated Data Verification
Data validation operates on two levels: syntactic validation (e.g., ensuring dates follow the MM/DD/YYYY format or Social Security numbers are nine digits long) and semantic validation (e.g., making sure a project’s start date comes before its end date) [12].
To tighten input security, use allowlists to define acceptable inputs and enforce server-side validation [12][13]. At the database level, constraints play a critical role in maintaining data integrity:
- Primary keys uniquely identify each row.
- Foreign keys ensure relationships between tables remain intact.
- Check constraints validate specific rules, such as ensuring salaries are positive values [2][3].
For data transfers and storage, checksum algorithms like SHA-256 or CRC-32C can detect corruption or unintended changes during uploads, downloads, or transfers [1].
Automated monitoring tools continuously assess data for accuracy, completeness, and consistency. As Raymond Blum and Rhandeev Singh from Google SRE put it:
"The secret to superior data integrity is proactive detection and rapid repair and recovery" [4].
Platforms like Great Expectations can automate data quality checks, ensuring ongoing validation [2]. Beyond these measures, controlling access to data is another critical layer of protection.
Access Controls and Audit Trails
Strong access controls, rooted in the ALCOA+ framework’s principles of attribution and traceability, ensure that every data change is accountable. Role-based access controls act as the first line of defense, limiting unauthorized modifications. Administrative actions, such as recovering deleted data, should have strict permissions in place [4]. Using stored procedures to manage data access ensures all interactions follow predefined business rules.
Audit trails are indispensable for tracking changes. These logs record every modification - creation, updates, and deletions - capturing details like who made the change, when it occurred, and why [1][2].
To mitigate accidental deletions or software glitches, soft deletion methods can be employed. This approach marks data as deleted but retains it for 30–60 days before permanent removal, offering a buffer for recovery [4].
Backup Systems and Disaster Recovery
Timely recovery of data is essential for maintaining both durability and accessibility, as emphasized in the ALCOA+ framework. As Google SRE highlights:
"Focus on restore capabilities over mere backups" [4].
An effective backup strategy starts with defining Service Level Objectives (SLOs) for data availability and regularly testing restoration processes to ensure backups function as intended [4][11].
A tiered backup approach is recommended:
- Use frequent local snapshots for quick recovery.
- Store offsite, media-isolated backups to protect against system-wide failures. Media isolation - storing backups on independent platforms - prevents issues like software bugs from corrupting all copies simultaneously [4].
Point-in-Time Recovery (PITR) is another invaluable feature, enabling restoration to a specific moment before an incident occurred. This is especially critical when problems go unnoticed for some time [4]. Backups should also be encrypted to prevent unauthorized access, and automation should handle the entire backup process to meet Recovery Point Objectives (RPO) and Recovery Time Objectives (RTO) [11].
It’s important to note that replication alone is not a recovery solution. Automated syncing can propagate corrupted or deleted data across all replicas. For example, during a 2011 Gmail outage, users experienced four days of data unavailability. Google SREs suggest data unavailability should not exceed 24 hours to maintain user trust [4].
Tools and Technologies for Data Integrity
Choosing the right tools is essential for quickly identifying and addressing data corruption in production environments. By adhering to ALCOA+ principles, these tools ensure that data remains attributable, legible, and accurate throughout its lifecycle. They automate validation processes, maintain detailed audit trails, and streamline recovery efforts.
Electronic Batch Records and Compliance Platforms
Platforms like QT9 and Sware Res_Q simplify the creation and tracking of electronic batch records. These tools are especially beneficial in industries such as life sciences and manufacturing, where regulatory compliance is critical. By automating these processes, they reduce the manual workload while ensuring alignment with industry standards.
AWS Glue Data Quality takes automation further by using its Data Quality Definition Language (DQDL) to recommend and monitor validation rules tailored to your datasets. This makes managing data quality in cloud environments more efficient [1]. For cloud migrations, AWS Database Migration Service (DMS) provides automatic validation by comparing source and target data, ensuring discrepancies are caught early [1].
While compliance platforms focus on securing regulatory data, AI tools enhance this by identifying potential anomalies in both code and data before deployment.
AI Tools for Code and Data Integrity
Tools like ClackyAI support data integrity during development by offering real-time debugging and diagnostics. These tools can detect logic errors and data handling issues before they escalate into significant problems. For example, ClackyAI’s Pro plan, priced at $29 per month, includes features like automated unit testing and comprehensive codebase diagnostics, allowing developers to manage integrity across 15–20 tasks monthly [15].
One major advantage of AI-driven tools is their ability to analyze historical patterns and predict vulnerabilities before they lead to data compromises [15]. However, human oversight remains critical, as large language models can have hallucination rates of 20%–30% [16].
Tool Comparison by Features and Costs
The table below outlines the features, pricing, and limitations of various tools used for data integrity:
| Tool Category | Key Features | Pricing Model | Primary Limitations |
|---|---|---|---|
| EBR (e.g., QT9) | Electronic batch records, automated compliance, audit trails | Enterprise/Subscription | High implementation overhead |
| Compliance (e.g., Sware Res_Q) | Automated validation, regulatory alignment, risk management | Subscription-based | Requires specific workflow integration |
| AI Coding Agents (e.g., ClackyAI) | Real-time debugging, codebase diagnostics, automated unit testing | $29/month (Pro) | Limited by AI context window |
| Database Constraints (Oracle/SQL) | Primary/Foreign keys, Check constraints, NOT NULL | Included with DB | Can impact write performance if complex |
| Data Quality (AWS Glue/Great Expectations) | Automated rule recommendation, statistics, alerting | Pay-per-use / Open Source | Requires initial rule definition |
For example, Snowflake offers advanced recovery options like Time Travel, which allows data restoration for up to 90 days on the Enterprise Edition. However, storage costs increase with longer retention periods [14]. Similarly, Oracle AI Database uses declarative constraints at the schema level to enforce data integrity more efficiently than application-level validation, though it requires careful planning during schema design [3][5].
When evaluating tools, it’s essential to first define your Recovery Point Objectives (RPO) and Recovery Time Objectives (RTO). This ensures you select solutions that meet your specific needs rather than opting for tools with unnecessary features. These comparisons provide a foundation for building a strategy that secures production data integrity in dynamic and complex environments.
Best Practices for Production Deployment
When deploying production-ready apps, precision and vigilance are key. Ensuring data integrity during deployment hinges on structured rollouts, real-time monitoring, and robust security measures that safeguard against both human error and system failures.
Monitoring and Continuous Validation
Effective monitoring is essential, and it should be structured into three key outputs:
- Pages: These require immediate human intervention for critical issues.
- Tickets: These represent bugs that need resolution within a few days.
- Logging: This captures data for later analysis and forensic investigations [7].
This tiered approach prevents alert fatigue while ensuring the team addresses issues based on their severity.
"The secret to superior data integrity is proactive detection and rapid repair and recovery." - Raymond Blum and Rhandeev Singh, Site Reliability Engineers, Google [4]
Deploy changes incrementally - start with 1% traffic, then gradually increase to 5% and 10%. This approach, combined with point-in-time recovery (up to 90 days), allows for quick rollbacks if issues arise [7][14]. If unexpected behavior occurs, roll back immediately before investigating further. Data pipelines should be designed to be idempotent - use operations like MERGE instead of INSERT to prevent duplication or corruption during retries [14]. Logging exceptions also helps trigger automated alerts and simplifies root-cause analysis [14].
Snowflake offers an additional safeguard with its non-configurable 7-day "Fail-safe" recovery period, which activates after standard Time Travel ends [14]. It's worth noting that even a 99.99% SLO for "good bytes" in a 2 GB artifact could still mean up to 200 KB of corrupted data - enough to wreak havoc on databases and executables [4].
Encryption and Security Measures
To protect data integrity, encryption must be applied in three states: at rest (stored), in transit (moving through networks), and in use (actively processed by applications) [18][20]. All database connections should mandate TLS encryption, and load balancers should be configured to use only HTTPS or TLS protocols [19][20].
Adopt Role-Based Access Control (RBAC) with the principle of least privilege, and require multi-factor authentication (MFA) for high-risk actions like deleting critical data buckets or snapshots [19][21]. Centralized key management services, such as AWS KMS, should be used, and a mandatory waiting period of 7 to 30 days should be enforced before permanently deleting keys. This precaution helps prevent irreversible data loss due to accidental deletions [19].
Soft deletion is another key safeguard. Instead of immediately purging data, mark it as deleted and retain it for 15 to 60 days [4]. This retention window is critical, as most account hijacking or data integrity issues are identified within this timeframe [4]. Additionally, maintain independent backup copies separate from replication systems, as replication can inadvertently propagate deletions or corruption across all nodes [4].
These measures integrate seamlessly with strong change management practices to ensure deployment stability.
Versioning and Change Management
A clear separation between the build, release, and run stages is essential for repeatable and traceable deployments [17]. Systems should be designed to "fail sanely" by validating and sanitizing configuration inputs. When bad input is detected, the system should revert to the last known-good state while alerting operators [7].
To prevent cascading failures during peak loads, implement capacity planning and retry strategies [7]. Assign resource monitors to production warehouses with credit quotas and "suspend_immediate" thresholds to avoid service disruptions caused by runaway queries [14].
Regularly conduct automated drills to test business continuity and disaster recovery plans. These drills ensure that both technical systems and operational procedures are ready for real incidents [14]. Additionally, establish out-of-band validation checks to catch gradual data corruption, which can occur over weeks and is far harder to detect than sudden deletions [4].
Conclusion: Key Takeaways on Data Integrity Standards
Data integrity forms the backbone of user trust and business success. When users face issues like data loss, corruption, or extended downtime, their confidence in your service takes a hit [4]. Interestingly, while organizations that prioritize data trust are twice as likely to achieve their business goals, only 13% are fully leveraging their integrity efforts [22].
The ALCOA+ framework stands out as a reliable approach for maintaining data accuracy, consistency, and traceability throughout its lifecycle. By enforcing integrity at the system level - using database constraints like primary keys, foreign keys, and check constraints - rather than relying solely on application code, organizations can build a more robust foundation [3][5]. Complement these measures with input validation, automated data verification, and thorough audit trails to identify and address issues before they escalate into larger problems.
Modern tools also play a critical role in upholding data integrity. Cloud services like AWS and Snowflake offer built-in features such as checksum algorithms and automated quality monitoring [1][14]. Additionally, platforms like ClackyAI provide AI-driven diagnostics and a comprehensive understanding of the entire codebase, ensuring data integrity is maintained from development through continuous updates with real-world users.
"The secret to superior data integrity is proactive detection and rapid repair and recovery." - Google SRE [4]
Beyond technical solutions, strategic practices are essential for building resilience. While 88% of organizations recognize the importance of trust between data producers and consumers, only 52% have taken concrete steps to act on it [22]. Defense-in-depth strategies, such as soft deletion windows (15–60 days), point-in-time recovery, and regular disaster recovery drills, can give your organization a competitive edge. Focus on rapid recovery capabilities rather than just backups - because how quickly you can restore data often determines user retention.
FAQs
What are the ALCOA+ principles, and why are they important for ensuring data integrity in production applications?
The ALCOA+ principles are a set of guidelines designed to uphold data integrity in regulated industries. The acronym represents Attributable, Legible, Contemporaneous, Original, and Accurate, with the "+" adding Complete, Consistent, Enduring, and Available. Together, these principles ensure that data remains reliable, traceable, and trustworthy.
In practical terms, these principles are brought to life through technical controls like role-based access, audit trails, and real-time logging. For instance, Attributable ensures every data modification is linked to a specific user or system, while Complete and Enduring rely on effective backups and long-term storage solutions. Tools such as ClackyAI make this process easier by automating critical tasks like data validation, audit logging, and secure authentication. This allows teams to meet these standards efficiently while creating dependable, production-ready applications.
What are the risks to data integrity caused by human errors and system failures, and how can these be prevented?
Human mistakes - like entering wrong data, misconfiguring schemas, or skipping validation steps - can create inaccurate or inconsistent records. On the other hand, system failures such as hardware crashes, software glitches, or ransomware attacks can corrupt files, lose transactions, or disrupt data relationships. These problems compromise the reliability of production systems and could lead to expensive errors or even compliance breaches.
To reduce these risks, consider implementing safeguards. For instance, database constraints like primary and foreign keys, along with application-level validations, can help catch issues early. Automated testing pipelines are another powerful way to detect errors before they escalate. Leveraging ACID-compliant storage formats ensures data consistency, while designing systems with fault tolerance in mind can help them withstand unexpected failures. Regular backups, encrypted audit logs, and automated recovery processes are also crucial for minimizing downtime and guarding against unauthorized changes. Tools like ClackyAI make this easier by embedding these protective measures into production-ready code, keeping data integrity intact from the beginning.
What are the best tools and strategies for ensuring data integrity in cloud-based applications?
Ensuring data integrity in cloud-based applications means implementing strategies and tools that protect data accuracy, consistency, and security. A vital step is using encryption both at rest and in transit, along with managed key management services. This ensures data remains secure as it moves between systems. Major cloud providers, such as AWS and Google Cloud, offer features like versioned object storage, tamper-evident logs, and automated monitoring, which help prevent unauthorized changes and maintain a clear audit trail.
Distributed databases with strong consistency guarantees, like TiDB, play an essential role in preserving logical integrity across nodes, especially in environments where failures or delays can occur. For broader data governance, platforms like Atlan offer automated quality checks and lineage tracking, ensuring data stays accurate, complete, and up-to-date throughout its lifecycle. Adding immutable backups and checksum verification to these practices creates a layered defense, delivering a reliable approach to maintaining data integrity in cloud environments.